
Microsoft has revealed a tool that can simulate a person’s voice and speech when given just three seconds of sample audio to base it off.
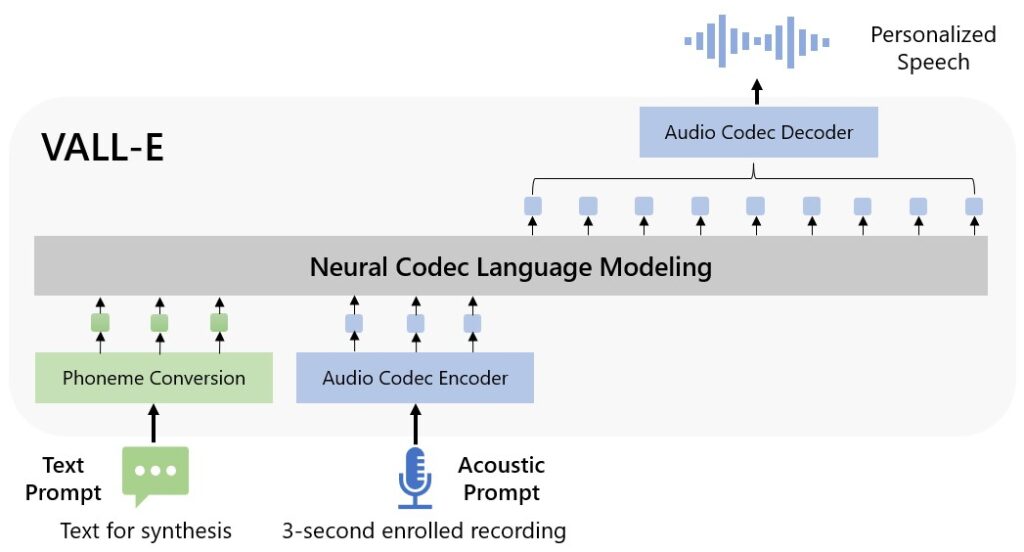
The VALL-E tool is a natural codec language model, the researches say, and can be used to synthesise speech. The idea is to improve text-to-speech capabilities and make it sound a little more natural.

Virgin Media Broadband Deal
As part of Virgin Media’s ongoing sale, you can get a whopping 132Mbps download speed average for just £15 a month for the first six month, bumping up to £30 a month thereafter. The contract lasts for 24-months and there’s a £9.99 installation fee but for such high speeds, this is an ideal buy for large households.
- Virgin Media
- 132Mbps average speeds
- £15/month for 6 months
In a post on GitHub, Microsoft says even with the very limited sample of speech, the technology is capable of maintaining the authenticity and emotion in the voice.
Whether the speaker is angry, amused, disgusted, or sleepy VALL-E can have a pop at maintaining the emotion when it simulates the voice. It’s not perfect yet, far from it, and seems to have problems with some of the stronger accents, but all in all it’s quite impressive for a proof of concept.
The company trained the tool using technology created by Meta, called LibriLight. It has 60,000 hours of English language speech from 7,000 speakers. Meta created the tech to attempt to fill in the gaps on audio calls when the signal is poor, but Microsoft has other goals in mind.
As with anything AI-related, there will be fears the technology could be misused to make it appear as if someone has said something they haven’t. This is something we’ve already experienced with video deepfakes.
However, if the technology is used for the right reasons, it could help people who have lost their voice communicate with others again in their own speech.
You can’t try it for yourself yet, but Microsoft has released a lot of samples (via Ars Technica) showcasing the technology.
In a post explaining the trials Microsoft says: “VALL-E emerges in-context learning capabilities and can be used to synthesize high-quality personalized speech with only a 3-second enrolled recording of an unseen speaker as an acoustic prompt. Experiment results show that VALL-E significantly outperforms the state-of-the-art zero-shot TTS system in terms of speech naturalness and speaker similarity. In addition, we find VALL-E could preserve the speaker’s emotion and acoustic environment of the acoustic prompt in synthesis.”
You might like…




Editorial independence
Editorial independence means being able to give an unbiased verdict about a product or company, with the avoidance of conflicts of interest. To ensure this is possible, every member of the editorial staff follows a clear code of conduct.
Professional conduct
We also expect our journalists to follow clear ethical standards in their work. Our staff members must strive for honesty and accuracy in everything they do. We follow the IPSO Editors’ code of practice to underpin these standards.
Editorial independence
Editorial independence means being able to give an unbiased verdict about a product or company, with the avoidance of conflicts of interest. To ensure this is possible, every member of the editorial staff follows a clear code of conduct.
Professional conduct
We also expect our journalists to follow clear ethical standards in their work. Our staff members must strive for honesty and accuracy in everything they do. We follow the IPSO Editors’ code of practice to underpin these standards.