Verdict
Key Specifications
- Review Price: £229.00
The past few weeks have been somewhat chaotic in the technology industry. Not only were nVidia and AMD both set to launch two new graphics cards within weeks of each other, which is bad enough, but we also had the peculiar legitimised leaked launch of the HD4850, which allowed performance figures and card shots but not architectural explanations, and then, out of the blue, nVidia also announced the 9800GTX+ which is a die-shrunk, higher-clocked version of the existing 9800 GTX. All of which leaves muggins here feeling a little cross eyed and sore of head.
The best solution, it was deemed by yours truly, was to ignore all the wailing and gnashing and just get down to the basic business of churning through reviews. First up was nVidia’s enormous, expensive, and incredibly fast high-end card, the GTX280, which is based on its GT200 chip. Now, it’s the turn of ATI with its RV770 chip that will be coming to market as the HD4870 and HD 4850 cards. 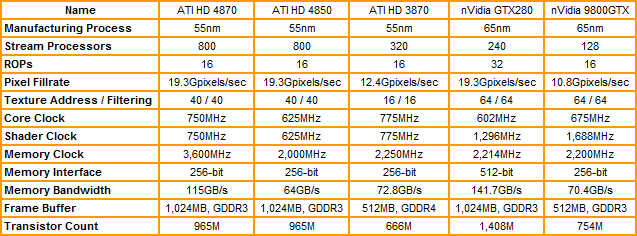
Both will feature 800 Stream Processors, 40 texture units, and 16 ROPs all of which we’ll talk about in more detail shortly. What essentially differentiates the two cards is clock speeds, memory configurations, and price (obviously). HD 4870 will be clocked at 750MHz, use 900MHz (3600MHZ effectively) GDDR5 memory and cost around £230. Meanwhile HD 4850 will run at 625MHz, use 993MHz (1986MHz effectively) GDDR3 memory, and will cost £130.
These prices are in drastic contrast to the two cards based on GT200 that nVidia just launched; GTX 280 is selling for over £400 and the GTX260 is around £260. So, once again it would seem ATI has come up short when it comes to performance and is trying to undercut nVidia instead. Well that’s one way of looking at it but ATI sees things a little differently. 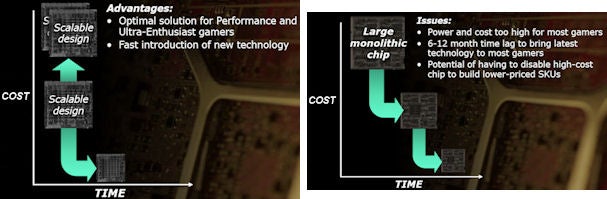
The traditional way graphics cards have been developed is to aim for the top with large expensive chips that win performance awards. The lower performing mainstream chips are then rolled out a few weeks or months down the line. However, with RV770, ATI is saying it has intentionally developed a smaller less powerful chip than GT200 because it’s aiming for the more lucrative performance/mainstream market – the type of people that will be willing to spend £100 to £200 – rather than the ultra high-end folk that will be willing to fork out £400+.
Whether that’s true or if it’s all just marketing spin, I’ll leave to you to decide, but it certainly makes sense in a way. True, the margins in this sector of the market aren’t as high as the ultra high-end but the volume is orders of magnitude larger. In the meantime ATI can work on its upcoming HD4870 X2 (or whatever it will be called) that will combine two RV770 chips on one board and leverage ATI’s more and more impressive Crossfire performance to create a single board that will compete at the high-end. 
The other reason I’m inclined to believe that ATI isn’t just spinning is because RV770 looks like a seriously competitive solution. In fact ATI could easily have got away with charging considerably more for this card. That and it makes sense to move away from large monolithic GPUs and work on multi-GPU solutions as they’re considerably more scalable. If ATI can master its multi-GPU solutions to the point where they work seamlessly (i.e. games developers and driver teams don’t have to optimise their software) it will be able to produce cheaper, more powerful cards than ever before.
Much as nVidia did with GT200, ATI has taken the basics of its previous generation architecture and added a bit more here, taken away a bit there, and generally optimised the whole lot to better suit modern, real world, performance needs. And, just as was the case with GT200, explaining the differences requires delving fairly deep into how the whole chip works. So, let’s start from the bottom and work our way up.
The core grunt work of RV770 is performed by its Stream Processing Units (SPU). These are largely similar to the Stream Processors used in nVidia’s latest architecture – they each contain three basic Arithmetic Logic Units that can power through simple floating point mathematical calculations like add and multiply. Even here there are differences in exactly how the two manufacturers perform these calculations but they’re similar enough to compare. It’s as we zoom further out that the two architectures really start to diverge. 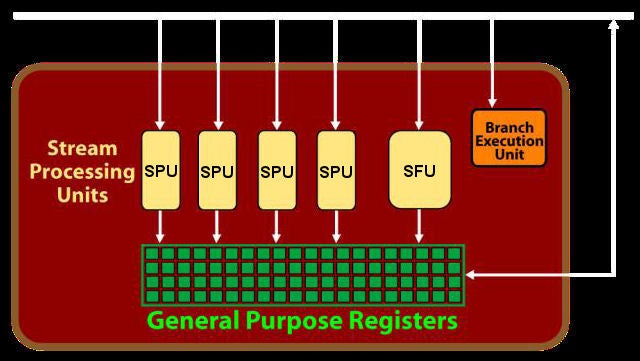
The next step up for the RV770 is what I’m calling the Multi Stream Processing Unit (MSPU). This contains four of the basic SPUs along with a fifth, Special Function Unit (SFU) that can do everything the other SPUs can do plus perform transcendental calculations like logarithms and trigonometrics.
Although the MSPU incorporates a number of processing units it is in many ways only the equivalent of a single Stream Processor from nVidia’s architecture. This is because, while an MSPU can perform up to five calculations per cycle, all those calculations have to be on the same thread. So unless the thread can be efficiently broken down the whole MSPU might only be as fast as one of nVidia’s SPs. Conversely, this is why nVidia runs its shaders at a much higher speed than ATI – to counter those situations where ATI’s many processors can perform calculations faster.
(centre)”ATIs SIMD core”(/centre)
Zooming out another step we see a Single Instruction Multiple Data (SIMD) core that from the outside looks similar to nVidia’s Streaming Multiprocessor (SM). Both contain a cluster of processing units, a thread sequencer and a few data stores. However, there are a number of places where the two differ. 
(centre)”nVidias Streaming Multiprocessor (SM)”(/centre)
For a start, ATI includes (four) texture processing units within the SIMD whereas nVidia does texturing further up the ladder. Each texture unit can perform one address lookup and one filtering operation per clock cycle. While this is essentially the same as RV670 (indeed the whole chip is largely identical up to this point) a few hidden improvements have been made. ATI claims performance per mm^2 has increased by 70 per cent through some untold tweaking. Also, additional L1 texture cache memory has also been dedicated to each SIMD making for a significant increase in texture cache bandwidth.
What can we say about Counter-Strike: Source that hasn’t been said before? It is simply ”the” benchmark for team-based online shooters and, four years after its release, it’s still one of the most popular game in its genre. In complete contrast to Enemy Territory: Quake Wars, it focuses on small environments and incredibly intensive small-scale battles with one-shot kills the order of the day. If you want to test all elements of your first person shooter skills in one go, this is the game to do it.
We test using the 32-bit version of the game using a custom timedemo taken during a game against bots on the cs_militia map. This has a large amount of foliage, so transparency antialiasing has a significant impact on image quality and performance, and is generally one of the most graphically intensive maps available. We find a framerate of at least 60fps is required for serious gaming as this game relies massively on quick, accurate reactions that simply can’t be compromised by dropped frames.
All in-game settings are set to their maximum and we test with 0xAA 0xAF, 2xAA 4xAF, and 4xAA 8xAA. Transparency anti-aliasing is also manually turned on through the driver, though this is obviously only enabled when normal AA is being used in-game.
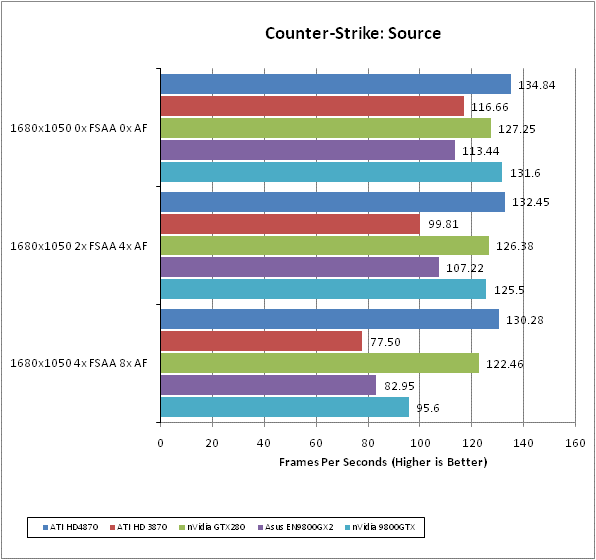
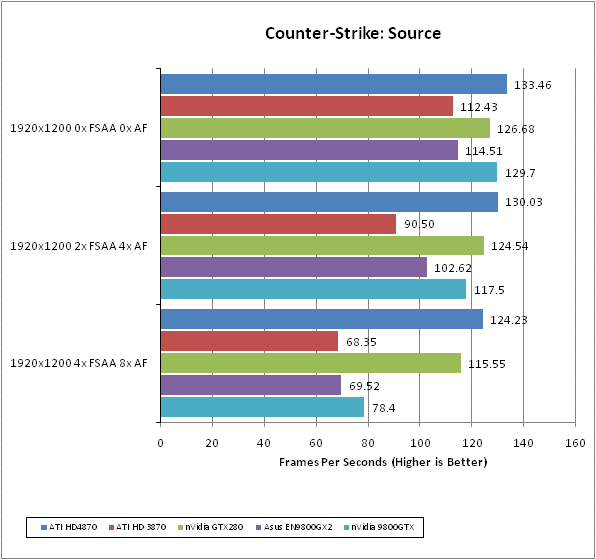
Counter-Strike: Source has always been a strong area for ATI’s recent cards so it’s no surprise to see the HD 4870 doing well here. However, having it beat every other card across the board is still quite a turn up for the books.
Call of Duty 4 has to be one of our favourite games of last year. It brought the Call of Duty brand bang up to date and proved that first person shooters didn’t need to have the best graphics, or the longest game time. It was just eight hours of pure adrenaline rush that constantly kept you on edge.
We test using the 32-bit version of the game patched to version 1.4 FRAPS is used to record framerates while we manually walk through a short section of the second level of the game. We find a framerate of 30fps is quite sufficient because, although the atmosphere is intense, the gameplay is less so – it doesn’t hang on quick reactions and high-speed movement.
All in-game settings are set to their maximum and we test with 0xAA and 4xAF. Transparency anti-aliasing is also manually turned on through the driver, though this is obviously only enabled when normal AA is being used in-game.
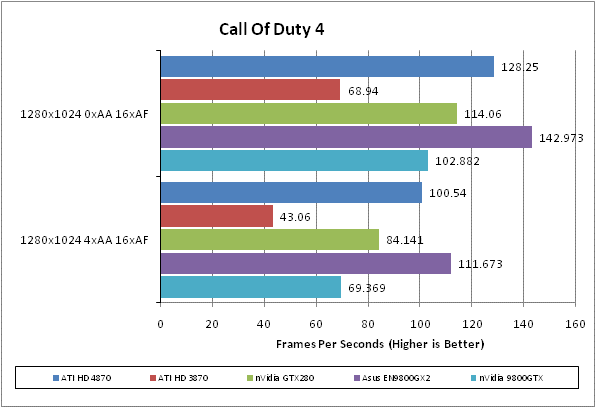
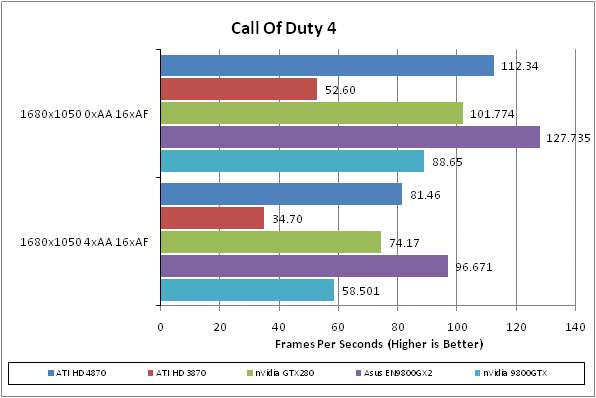
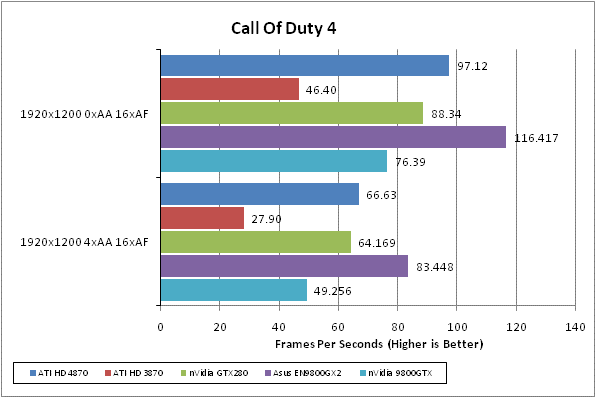
More success for the HD 4870 here. It’s again beaten by the GTX 280 but that’s the only card it falls behind and, again, it crucially beats out the 9800GTX.
Enemy Territory: Quake Wars distinguishes itself from all our other tests by the fact it uses the open source OpenGL API rather than Microsoft’s DirectX. It’s a team-based first person shooter set in a dystopian future war scenario. As a player you get to choose from an enormous range of character types and playing styles, and there’s a whole host of vehicles to choose from too. Battles can span vast areas of open space and involve a huge number of participants. All in all, it’s multiplayer heaven.
We test using the 32-bit version of the game, which is patched to version 1.4. We use a custom timedemo from the Valley level, which we feel is about as graphically intensive as the game gets. We feel a framerate of at least 50fps is required for this game as the intense multiplayer action and high speed mouse movement demands it.
All in-game settings are set to their maximum and we test with 0xAA 0xAF, 2xAA 4xAF, and 4xAA 8xAA. Transparency anti-aliasing is also manually turned on through the driver, though this is obviously only enabled when normal AA is being used in-game.
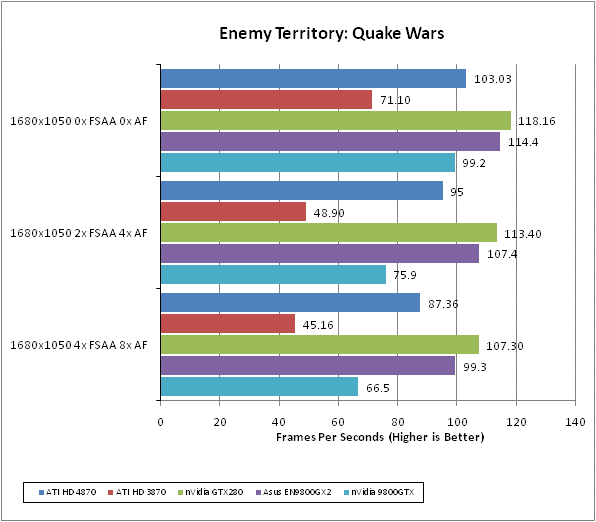
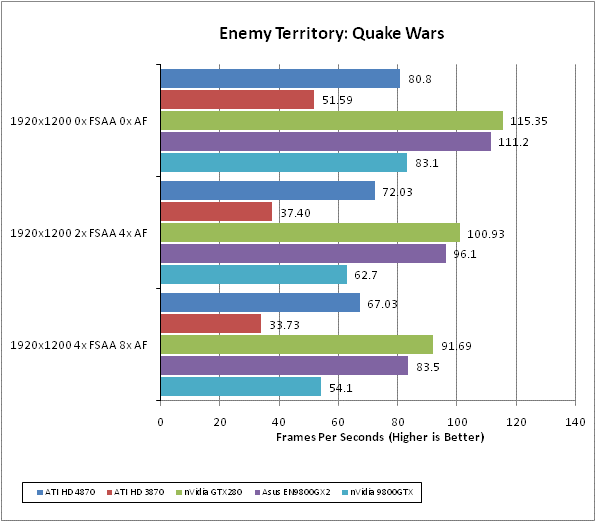
We knew it couldn’t last forever. ATIs traditional weakness in OpenGL titles is shown up as both nVidia’s top end cards soundly beat the HD 4870. That said, the HD 4870 does crucially beat the 9800 GTX across the board.
Race Driver: GRID is the newest game in our testing arsenal and it’s currently one of our favourites too. Its combination of arcade style thrills and spills with a healthy dose of realism and extras like Flashback makes it a great pickup and go driving game. It’s also visually stunning with beautifully rendered settings, interactive crowds, destructible environments, and stunning lighting. All that and it’s not the most demanding game on hardware, either.
We test using the 32-bit version of the game, which is unpatched and running in DirectX10 mode. FRAPS is used to record frame rates while we manually complete one circuit of the Okutama Grand Circuit, in a Pro Tuned race on normal difficulty. We find a framerate of at least 40fps is required to play this game satisfactorily as significant stutters can ruin your timing and precision. We’d also consider 4xAA as a minimum as the track, barriers, and car bodies suffer considerably from aliasing and are a constant distraction.
All in-game settings are set to their maximum and we test with 0xAA, 4xAA, and 8xAA. Transparency anti-aliasing is also manually turned on through the driver, though this is obviously only enabled when normal AA is being used in-game.
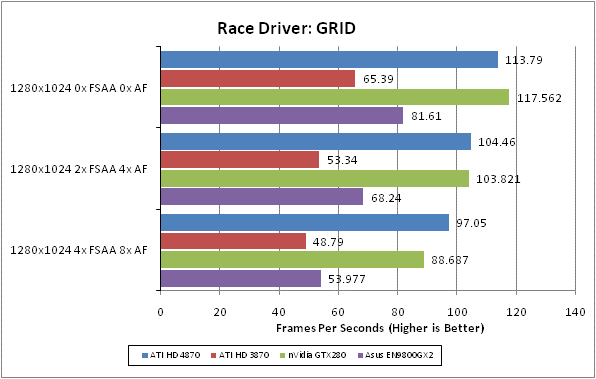
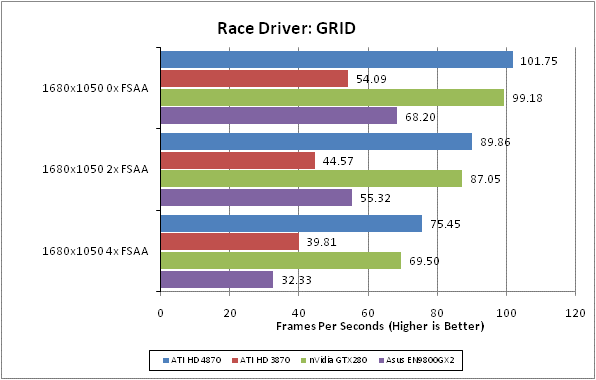
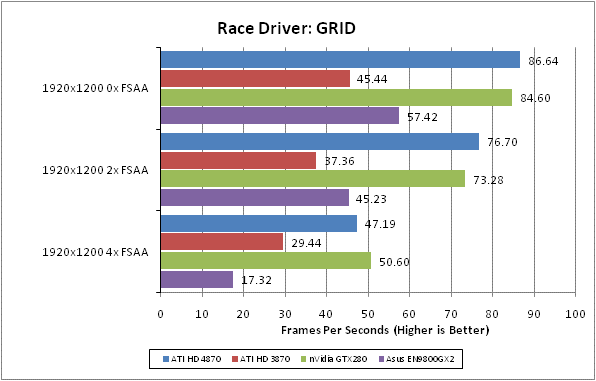
The good news continues for ATI in this title, even given our limited test subjects. So much does the HD 4870 like this game that it even beats nVidia’s flagship GTX 280. This is hugely impressive stuff.
While it hasn’t been a huge commercial success and its gameplay is far from revolutionary, the graphical fidelity of Crysis is still second to none and as such it’s still the ultimate test for a graphics card. With masses of dynamic foliage, rolling mountain ranges, bright blue seas, and big explosions, this game has all the eye-candy you could wish for and then some.
We test using the 32-bit version of the game patched to version 1.1 and running in DirectX 10 mode. We use a custom timedemo that’s taken from the first moments at the start of the game, wondering around the beach. Surprisingly, considering its claustrophobic setting and graphically rich environment, we find that any frame rate above 30fps is about sufficient to play this game.
All in-game settings are set to high for our test runs and we test with both 0xAA and 4xAA. Transparency anti-aliasing is also manually turned on through the driver, though this is obviously only enabled when normal AA is being used in-game.
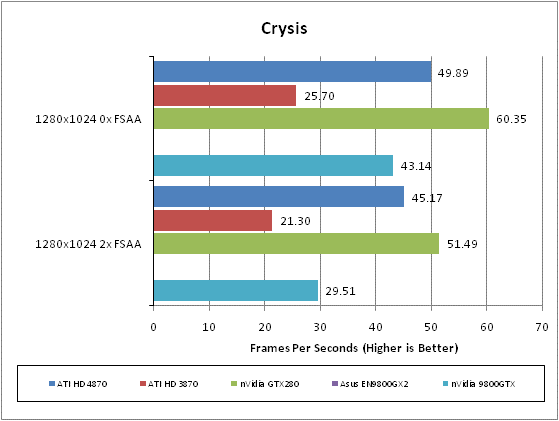
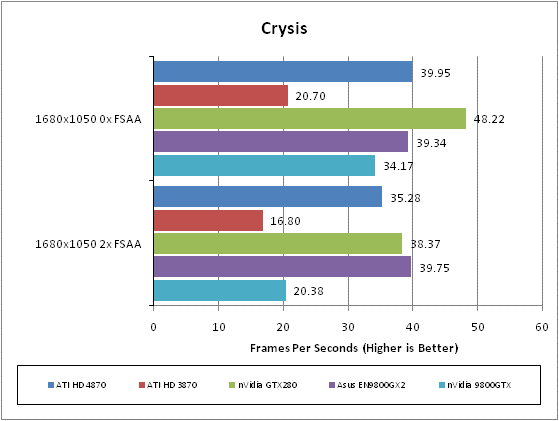
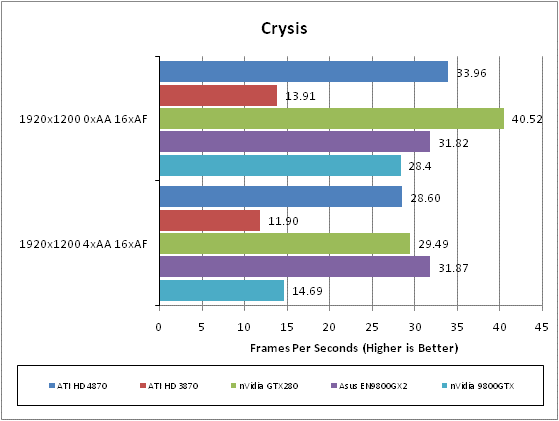
Wow, what a start for HD 4870. In a game that ATI’s cards used to really struggle with, the HD 4870 has leapt into third place behind the GTX 280 and 9800GX2. Most importantly it has beaten nVidia’s nearest priced competitor, the 9800GTX, by some margin – especially when AA is applied – and has more than doubled the HD 3870’s performance.
As I did with my recent GTX 280 review, I’m going to put the whole GPGPU performance debate to one side and concentrate on good ol’ gaming performance for now. When more GPU accelerated software becomes available we’ll take another look at this hardware.
Our tests use a variety of manual run throughs and automated timedemos but regardless of which test method is used we run through multiple times and ensure results are consistent. The average of our consistent runs is then reported to you. The test setup is as follows:
”’Common System Components”’
* Intel Core 2 Quad QX9770
* Asus P5E3
* 2GB Corsair TWIN3X2048-1333C9 DDR3
* 150GB Western Digital Raptor
* Microsoft Windows Vista Home Premium 32-bit
”’Drivers”’
* GTX280: Forceware 177.34
* Other nVidia cards: Forceware 175.16
* ATI: Catalyst 8.4
”’Cards Tested”’
* HIS ATI Radeon HD 4870
* ATI HD 3870
* nVidia GeForce GTX 280
* nVidia GeForce 9800 GX2
* nVidia GeForce 9800 GTX
”’Games Tested”’
* Crysis
* Race Driver: GRID
* Enemy Territory: Quake Wars
* Call of Duty 4
* Counter-Strike: Source

One of the headline features of R600 was its 512-bit wide ring-bus memory controller. This gave unprecedented memory bandwidth and was something ATI was very proud of at the time. However, it was a very silicon-expensive design that didn’t use its resources very efficiently. So, for RV770, ATI has gone back to the drawing board and come up with a completely new (though actually fairly conventional) memory controller design. 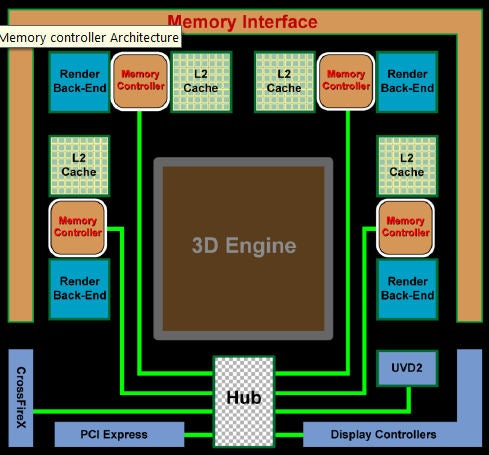
A central hub allows memory to be accessed from any part of the chip but the actual controllers have been moved to the edge of the chip where they’re next to the most memory-bandwidth hungry parts. For low memory usage parts like the CrossfireX interconnect and UVD2 controllers, memory access is handled directly by the hub. By combining this new configuration with the latest GDDR5 memory (at least for the HD 4870) ATI has reduced latency and increased bandwidth to a colossal 192GB/s – nearly twice that of R600.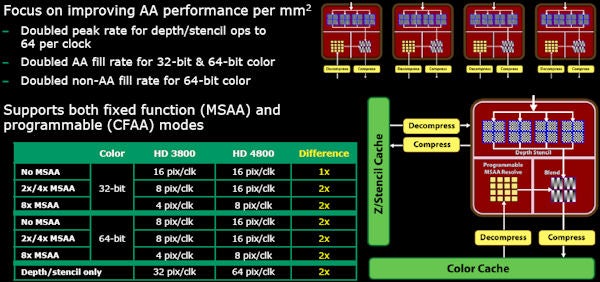
Another key change in RV770 is the improved AA performance. ATI went back to the drawing board when designing the ROPs and in particular greatly increased dedicated AA hardware. On R600 and RV670, dedicated AA hardware was poor and AA more often than not was performed using the shaders, which had a massive impact on performance.
Energy efficiency has also been improved thanks to clock gating that reduces the clock frequency of the card when not gaming or doing intensive GPGPU work. It would seem these improvements work, as well…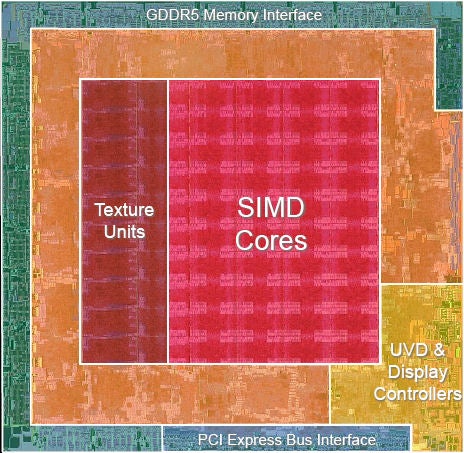
Finally, let’s finish our look at the features of RV770 with another one of those lovely overlaid die shots. As with the similiar shot we looked at of GT200, the unmarked section (in this instance coloured in orange) will be a miscellany of other control logic like the thread scheduler and raster setup.
While ATI actually saw fit to announce and release the slower HD 4850 card first, by now both this and the faster HD 4870 cards will be available. So, in this article Im’ going to focus on the flagship HD 4870.
For our review we were provided with a card made by HIS but the card is the exact same design as that used on ATI’s reference board except for a little HIS sticker in the centre of the fan. This is a common situation for early cards based on new architecture and we can expect to see more exotic coolers and overclocked cards appearing in the coming months. 
The retail bundle provided with this HIS card is worth a special mention. While the inclusion of DVI-to-HDMI, DVI-to-VGA, S-video-to-composite, and S-video-to-component adapters are all standard fare, the funky little screwdriver is definitely worthy of praise. It incorporates a spirit level, two interchangeable magnetic driver bits that each have a large and small head, and a little LED torch. It’s no Leatherman, admittedly, but it is a useful multi-tool to have next to your PC. You also get a license that enables you to get a free copy of Half-Life 2: Lost Coast and Half-life 2: Deathmatch via Steam but there are no ”proper” games included. 
The card itself is a dual-slot design that looks very similar to the HD 2900 XT – evidently the revised cooler used on the HD 3870 wasn’t all that. The PCB is 242mm in length, which is long but not excessively so and the whole card weighs a hefty 1.25kg, which is again high but not uncommonly so.
We’ve come to expect good things from both nVidia and ATI with their high-end coolers recently and the HD 4870 is no exception. Yes it gets loud when under load but then we’d expect you to be wearing headphones anyway and it’s certainly not loud enough to disturb anyone in the room next door. When idle it is near silent and the fan also reacts to temperature so it will only ever be as loud as needs be. The card seems to run hotter than the GTX280 when it’s good and busy but the dual slot design should ensure not too much of that heat builds up in your case (which would eventually lead to overheating and stability problems).
Along the top edge are two conventional CrossfireX connectors. The card can be used for CrossfireX configurations with up to three (maybe four if you can fit them on a board) cards running in tandem.
Power requirements are fairly hefty with two six-pin PCI-Express connections required to get the card up and running. You can get dongles that convert two Molex connectors to one of these six-pin connectors but you’ll still a decent high-wattage power supply in the first place. 
Elsewhere there is really very little that’s extraordinary about the HD 4870. Outputs are the standard 2x dual-link DVI-D along with an analogue output that supports S-Video natively and component and composite via dongles. The DVI connectors are HDCP compliant to enable Blu-ray playback and the audio-over HDMI capabilities from previous ATI cards are also present. In fact, ATI has upgraded the audio capabilities to enable eight-channel LPCM for full 7.1 surround configurations.
As well as the difference in texturing configuration, the SFUs in nVidia’s architecture only appear at this point whereas there is an SFU in each MSPU in ATI’s architecture. So, for every SIMD you get 16 SFUs whereas as each SM only has two. 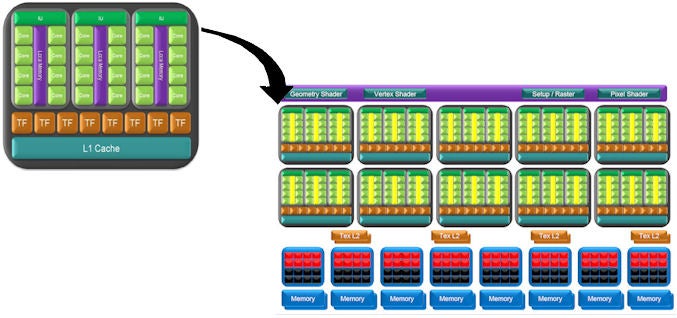
(centre)”nVidia combines 10 TPCs to create the shader power of GT200”(/centre)
Moving out a further step, things look even more different. Whereas nVidia combines three SMs and adds texturing capabilities (eight per TPC) to create a Texture/Processing Cluster (TPC) then combines 10 of these. ATI on the other hand skips straight to adding 10 SIMD cores together. The result is RV770 ends up with 640 SPUs, 160 SFUs (remember these can also do everything the SPUs can), and 40 texture units whereas GT200 has 240 SPUs, 60 SFUs, and 80 texture units. In comparison, R600 and RV670 had four SIMDs, making for a total of 256 SPUs, 128 SFUs, and 16 texture units. 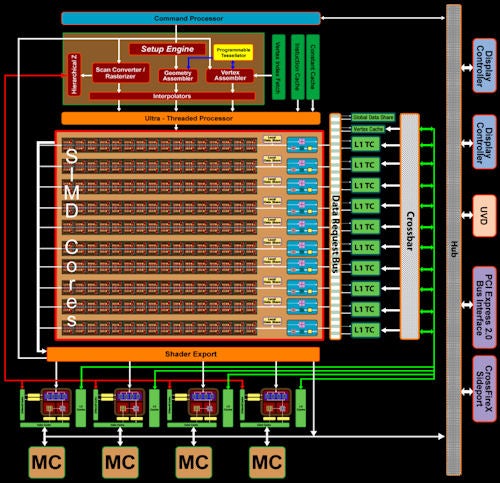
(centre)”ATI uses 10 SIMDs to create the shader power of RV770”(/centre)
Now it only takes a brief glance at those numbers to realise that somewhere along the way nVidia and ATI’s tactics have massively differing results as ATI doesn’t even pretend the 800 (640 + 160) SPUs in RV770 come close to competing with the 240 on GT200. We already mentioned that ATIs SPUs can only work on one thread at a time, so in many ways the 800 total SPUs could be considered to only have the same processing power as 160 SPs, which does more closely reflect average real world performance figures.
However, it’s not quite as simple as that. If software is written in such a way that it benefits from the extra processors in ATI’s architecture then it will run considerably faster, if it isn’t then it will be slower than nVidia’s cards. The only real conclusion we can draw at the moment is that nVidia’s ”simpler” approach will likely give more consistent performance in the short term. If software developers begin to embrace more complicated routines than ATI’s hardware could pull away in the long term.
The same is true when you consider RV770 vs GT200 for GPGPU applications. While RV770 has theoretically more compute power, at 1.2 TeraFLOPs compared to GT200s 933GigaFLOPs, it requires programs to be written in such a way that they take full advantage. Time, and future benchmarks, will tell which turns out to be the ”best” method.
With RV770 ATI has taken a slightly different approach to graphics card design. Rather than aiming for the top end it’s gone straight for the lucrative ~£200 market and produced a card that fits the bill perfectly. Performance is exceptional for the price and certainly better than we’d expected. Especially when you look at the improvement over ATIs previous efforts. 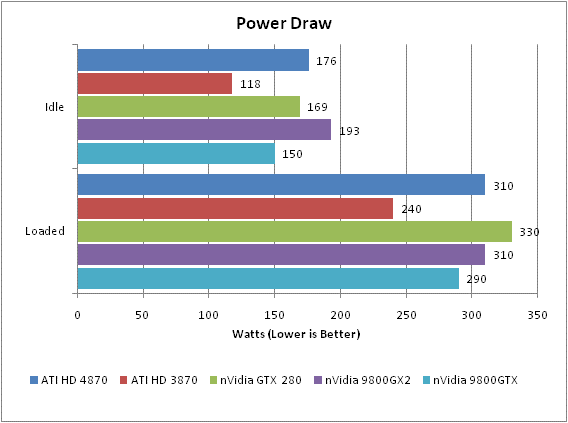
Of course, ATI isn’t completely neglecting the high-end market and in a few months time we’ll be seeing a card, codenamed R700, that will use two RV770 chips on one board. And, bearing in mind the performance of a single HD 4870 card, it looks like it may bring down nVidia’s dominance at the top end. Even if it doesn’t, though, at least it’ll drive prices down across the market. For the time being, though, we can’t fault the HD4870 on performance for the price. 
It’s the same story when we consider the rest of the cards’ characteristics. Power usage is very low when idle, which is accompanied by the fans running near silently, and although this ramps up when the card is hard at work it’s never enough to be a concern.
If the look of a graphics card is something that concerns you then we’d have to admit the HD 4870 does fall down when compared to the sleek black of nVidia’s cards. We also like the protective shroud that nVidia has used on its GTX 280 and 9800GX2. It helps prevent physical damage and also reduces the chance of static shocks destroying internal components. However, being careful when installing your card nullifies the latter concerns and unless you have a window in your PC case the former will be of little long term consequence.
”’Verdict”’
We really, really like the ATI Radeon HD 4870. It offers unheard of performance for the price and is certainly a significant improvement over the HD 3870. So much do we like this card, in fact, that it runs away with our top, Editor’s Choice, award.
Trusted Score
Score in detail
-
Value 10
-
Features 10
-
Performance 8
Editorial independence
Editorial independence means being able to give an unbiased verdict about a product or company, with the avoidance of conflicts of interest. To ensure this is possible, every member of the editorial staff follows a clear code of conduct.
Professional conduct
We also expect our journalists to follow clear ethical standards in their work. Our staff members must strive for honesty and accuracy in everything they do. We follow the IPSO Editors’ code of practice to underpin these standards.
Editorial independence
Editorial independence means being able to give an unbiased verdict about a product or company, with the avoidance of conflicts of interest. To ensure this is possible, every member of the editorial staff follows a clear code of conduct.
Professional conduct
We also expect our journalists to follow clear ethical standards in their work. Our staff members must strive for honesty and accuracy in everything they do. We follow the IPSO Editors’ code of practice to underpin these standards.